¿Qué es la indexación de contenidos?
Se llama indexación de contenidos al proceso en que Google lee una url dentro de un dominio y la incluye en su índice. Esta página pasa a formar parte de su catálogo de contenidos. En otras palabras, un contenido está indexado cuando aparece en una búsqueda de Google.
La indexación de contenidos es uno de los principales objetivos del posicionamiento y una de las ramas de trabajo más importantes de un profesional del SEO en cualquier proyecto. Controlar en todo momento qué urls tiene Google en su índice y cuáles no es una tarea recurrente y muy manual. Tanto es así que puede lanzar al éxito o hundir en el fango cualquier dominio.
Consta de dos fases:
- El rastreo por parte de los motores de búsqueda. Es lo que también se conoce como crawling. Consiste en la navegación del bot de Google u otros por la web.
- El motor de búsqueda interpreta la página y su contenido. Pasa a formar parte de la base de datos de resultados y, desde ese momento, puede aparecer en las SERP.
¿En qué afecta una buena indexación?
Uno de los primeros análisis que realizamos al enfrentarnos a una nueva web es qué páginas deben aparecer en los resultados de Google y cuáles están apareciendo. Debemos asegurarnos de que los motores de búsqueda llegan a todas las páginas que queremos. Es vital entender que no siempre tienen que indexar todas las páginas de una web.
Si la indexación de un dominio está siendo la correcta, se evitarán casos de canibalización por duplicidad de contenidos, principalmente. Es uno de los problemas más básicos del SEO y puede echar por tierra una estrategia. Debemos ser capaces de diferenciar las urls tanto como para que Google entienda que deben posicionar por keywords distintas.
¿En qué afecta una mala indexación?
Lo contrario sucede si estamos indexando mal. Al focalizar todos los sectores en un sector, es común que haya páginas tratando temas muy similares. De hecho, los casos en los que suelen indexarse urls de más son los que no tienen control sobre los contenidos o no se trabaja con una estrategia.
Cuando tenemos contenidos indexados de más (ya sea por contenidos muy similares a otros o por errores técnicos), es normal que perdamos posicionamiento. Y, si vamos desapareciendo de las primeras páginas, bajará nuestro tráfico orgánico.
¿Cómo medir la indexación?
Considerar que estamos indexando bien o mal es una operación tediosa. Pero gracias al índice de Google y las capacidades de medición de datos de Google, disponemos de dos caminos relativamente rápidos.
Informe de indexación de Google Search Console
Esta es la primera vez que aparece Search Console pero no será la única. Esta herramienta de Google, principalmente útil para controlar el posicionamiento, da información muy relevante sobre indexación.
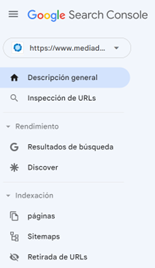
Sin entrar punto por punto a cada apartado del menú de Search Console, podemos ver un espacio para Indexación. En el primero de los apartados podemos conocer qué urls están perfectamente indexadas y cuáles no. Además, en los casos negativos, Google nos ofrece incluso la razón por la que está teniendo problemas.
Inspección de URL en Search Console
Otra de las funciones que ofrece Search Console es la posibilidad de comprobar cada caso de manera individual.

Al buscar cualquiera de las páginas que pertenezcan al dominio, aparecerá un cuadro como este indicando si está o no en el índice:
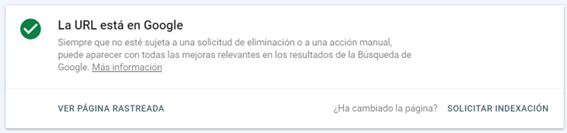
En todos los casos nos permite forzar la indexación. Ya sea porque no aparezca o porque hayamos hecho cambios y queramos que vuelva a pasar para actualizar la versión en el servidor.
Comando “site:dominio.com”
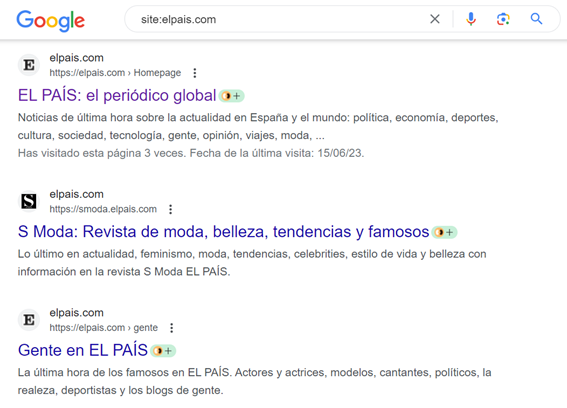
Por último, existe otro método que no es del todo fiable. Colocando esta fórmula en la caja de búsqueda obtendremos una lista de urls indexadas en nuestro sitio web, pero no todas. Si las urls aparecen ahí, están indexadas.
Como se aprecia en la captura, Google nos enlista páginas pertenecientes al dominio. ¡Ojo! Incluyendo todas las urls de subdominios y directorios. No es un método que nos dé todas las urls ni excesiva información.
Es útil para conocer la indexación de una url concreta o las urls que posicionan por una palabra clave si se utiliza este comando site:dominio.com «keyword».
Factores que facilitan la indexación
Ahora que sabemos cómo comprobar la indexación (o no) de una página, tenemos que aprender qué caminos nos llevan a que la página aparezca en Google. Hasta ahora se pueden utilizar 4 métodos diferentes para poner al servicio del motor de búsqueda las páginas y que haga lo que considere. Lo recomendable es utilizarlos todos. Es decir, son totalmente complementarios.
Búsqueda de url en Google Search Console
Este ya se ha comentado en el apartado anterior. Introducimos una url en Search Console, solicitamos su indexación y revisamos, pasado un tiempo (desde unas horas hasta unos días) si hemos conseguido que indexe. Una vez ahí, es cosa nuestra que mejore el posicionamiento.
Sitemaps
Esta es una de las formas técnicas que tenemos de facilitar la indexación. El sitemap es un listado de todas las urls de un sitio web que podemos colocar en diferentes herramientas. Al dejarlo en manos de Google, nos aseguramos de que conoce todas nuestras urls y que las rastreará tarde o temprano.
Las opciones para facilitar el rastreo son principalmente dos:
- Poner el sitemap en Google Search Console. La herramienta nos permite enviar todos los sitemaps que queramos de manera que acceda a las urls que queremos. Algunas extensiones como Yoast SEO dan la posibilidad de crear sitemaps diferentes según el tipo de contenidos (páginas, posts, categorías, etiquetas, etc.).
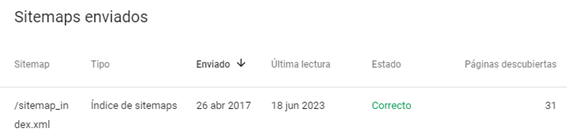
- Citar el sitemap dentro del archivo robots.txt. Entraremos en profundidad en el siguiente punto, pero, dentro de nuestro archivo para los robots, podemos indicar cuál es el sitemap principal y otros mapas del sitio interesantes.
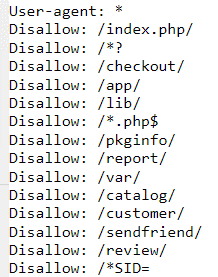
Robots.txt
La función principal de este archivo es dirigir la indexación e indicarle al Googlebot qué páginas debe leer y cuáles no. El robots.txt es la única manera real de mediar en el proceso.
En realidad, puede funcionar a nivel directorio y a nivel url. Además, tiene la capacidad de limitar los bots que te pueden rastrear. Se indica con algunas normas básicas por dónde debe navegar el robot.
Enlaces y arquitectura de página
Si nos centramos en la indexación natural, la que surge desde la pura navegación, tenemos que fiarnos de la buena elaboración de nuestra arquitectura web interna. La posición de los enlaces son los cables que van conectando unas páginas con otras y permiten que se descubra toda la web o solo una parte. Es por eso por lo que uno de los errores principales que surgen en el SEO son las páginas huérfanas. Una url sin enlaces es una url perdida en el medio del espacio. Google no sabe que existe ni cómo llegar hasta ella. Por lo que es muy complicado que indexe.
Es cierto que los enlaces externos pueden “rescatar” alguna página de este estilo. Pero lo más habitual es que estas páginas no aparezcan en ningún sitio. Por esta razón es importante el enlazado que se hace en una web y cómo se estructura el menú, el footer, el sitemap y el enlazado interno.
Desindexación de contenidos
Igual que podemos ayudar a Google a entender qué urls consideramos importantes, existen métodos de indicar cuáles son ‘negativas’. Lo más sencillo es mediante el robots.txt, como ya hemos indicado.
Pero la opción más ‘suave’ es mediante Search Console. Existe el apartado “Retirada de URLs” que nos permite pedirle a Google que no muestre más una determinada página. La herramienta enlista las urls que se han retirado por tu elección o por acción de los usuarios.
Por último, la opción más común y más rudimentaria es la eliminación de enlaces. Cuando eliminamos todos los links internos hacia una url concreta, conseguimos aislarla. De esta forma, los motores de búsqueda no pueden encontrarla y termina por desaparecer de los índices. Los casos en los que más se usa es con páginas rotas o contenidos que ya no vamos a necesitar más en un dominio. Suele ir acompañado de una redirección.
La parte gratificante del SEO es ver subir las conversiones en Google Analytics dentro del canal de Organic Search. Y primero debemos conseguir que las urls más importantes aparezcan en el buscador para después conseguir que posicionen por las keywords adecuadas.
